
SQL Group By
After having talked about all the SQL Aggregate functions, there's one more topic that goes hand in hand with what we've already learned… The group by keyword.
This particular keyword allows us to take a bunch of data and mash it all together into matching groups and then perform aggregate functions on those groups (like sum and avg).
You might ask yourself why you'd want to “mash together” a bunch of data. The answer to this is best explained with an example, but let me try to put it in regular words before we jump into our example. Grouping data together allows us to look at aggregate data in relation to unique piece of data (or rows), a typical use case would be to group all the matching data together so you can get a count of the number of occurrences of specific data. An example related to grouping and counting could be a presidential election, you'll have all the votes in a database and you'll want to group that data together to get the total votes for each unique candidate.
Grouping and counting is a very simple use case for the group by keyword, so the example that we'll be looking at in this post will be related to bank accounts and transactions. With bank accounts and transactions within those bank accounts, we can start to use the more complex grouping methodologies (which we'll be talking about later in this post).
Why use SQL Group By?
Grouping data together is extremely valuable in many ways. You'll see a few examples here that relate to bank accounts and transactions within those bank accounts.
Let's assume we have three different bank accounts and each has both credit and debit transactions. We would also like to see a quick summary of all the credits and all the debits for each bank account. This kind of “requirement” lends itself perfectly for grouping.
So let's first set up our example case in our database. We'll create the tables and columns as follows:
create table bank_account ( bank_account_id int(11) auto_increment primary key, bank_account_number varchar(20) ); create table transaction ( transaction_id int(11) auto_increment primary key, bank_account_id int(11), transaction_date date, debit_amount numeric(10,2) default 0.0, credit_amount numeric(10,2) default 0.0 );
Okay, so with our two tables created, now we need to input some test data to start demonstrating how the SQL group by keyword works.
insert into bank_account (bank_account_number) values ('A-283748293'); -- this will become bank_account_id 1
insert into bank_account (bank_account_number) values ('B-174984638'); -- this will become bank_account_id 2
insert into bank_account (bank_account_number) values ('C-927461738'); -- this will become bank_account_id 3
insert into transaction (bank_account_id, credit_amount, transaction_date) values (1, 250.12, '2014-06-10');
insert into transaction (bank_account_id, debit_amount, transaction_date) values (2, -123.93, '2014-06-10');
insert into transaction (bank_account_id, credit_amount, transaction_date) values (3, 832.11, '2014-06-11');
insert into transaction (bank_account_id, debit_amount, transaction_date) values (1, -100.32, '2014-06-10');
insert into transaction (bank_account_id, credit_amount, transaction_date) values (2, 322.33, '2014-06-11');
insert into transaction (bank_account_id, credit_amount, transaction_date) values (3, 131.92, '2014-06-11');
insert into transaction (bank_account_id, credit_amount, transaction_date) values (1, 142.50, '2014-06-12');
What the sql script above has done is just inserted three bank accounts into the bank_account table, and then it inserted a few transactions (both debit and credit) into each of the three bank accounts.
Alright, so with all of this data, it's easy to get a bit lost in the details of what's going on, right? Wouldn't it be nice if we could just get a breakdown of the balance of each account, based on all the transactions in our database table?
Well, that's actually pretty simple to do, as you would just perform a SUM operation on the credit_amount and debit_amount columns. You've already learned how to do this in the last SQL tutorial lesson on aggregate functions. But we also need to add the grouping logic in there to see the balance of each account.
Before we do that, let's take a look at how the data looks “as is” without grouping anything together. We'll execute a simple select statement on the transaction table:
select * from transaction;
After running this query, here's what the resulting values should look like in the transaction table:
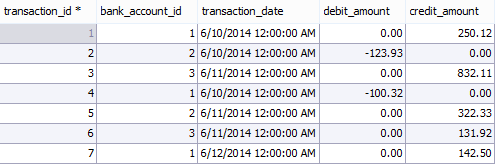
Do you see how the data is stored in the transaction table? Each individual transaction is given a date, it's associated with a specific bank account, and it's either marked as a debit or a credit based on which of the two columns are filled in. If it's a credit transaction, then the corresponding credit_amount column will have a positive dollar amount inserted, also the debit_amount column is set to 0.0 by default (as is seen in the table's definition where we set a default value for both the credit_amount and debit_amount)
But, like I said, this data is a bit too granular for our liking, so let's take a look at how we can group it together. Let's group this data by bank account number by using the group by keyword:
select b.bank_account_number, sum(t.debit_amount), sum(t.credit_amount) from bank_account b join transaction t on t.bank_account_id = b.bank_account_id group by b.bank_account_number;
After running this SQL script, here's what the resulting data looks like from the select:
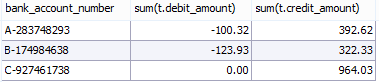
***CRITICALLY IMPORTANT THINGS to note about the SQL script above are***:
- Since we are grouping by
bank_account_numberwe are allowed to put it in the list of columns toselectfrom - Since we are using the
group bykeyword, we're also allowed to use the aggregate functions in our list of columns toselectfrom - We should not
selectany columns that aren't in the group by list of columns
What this means is that because I've stated to group by bank_account_number, this means I should not also show values for something like the transaction_date as the value displayed won't necessarily make sense.
Grouping By Other Columns
Let's say that we're not interested in knowing the debits and credits for each bank account, let's say that we're only interested in knowing the total of both the credits and debits for any given date. How would we accomplish this?
Well, there are two requirements that need to be address in that previous statement. We'll need to:
Group by transaction_date- Add up the credits with the debits for each individual
transaction_date
So, let's follow through on our new requirements with this sql script:
select t.transaction_date, sum(t.credit_amount + t.debit_amount) from bank_account b join transaction t on t.bank_account_id = b.bank_account_id group by t.transaction_date;
You should note that we changed the group by to be t.transaction_date (instead of b.bank_account_number) and we've also used the plus (+) symbol inside of our SUM aggregate function to add up the debits and credits.
Okay, so what do the results of this query look like?
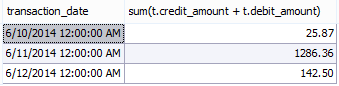
So as you can see here, our database has taken all the data in question, grouped it together by the transaction dates that match, and then once it had them all grouped into their proper “buckets” it performs the aggregate SUM function to give us our final result.
How to Visualize the SQL Group By Command
So to summarize this tutorial, I'd like to leave you with the trick I use to help me understand what's going on when grouping data. Whenever you have a column listed in the group by area, just think of having buckets for that particular group of data. You'll have a new “bucket” for each unique piece of data inside of the column you're grouping on.
So if we're grouping by bank_account_id, then I would picture three different buckets (since we have three different bank accounts). Then for every transaction that belongs to the first bank account, we'll “throw” that transaction into the first bucket. For every transaction that belongs to the second bank account, we'll “throw” it into the second bucket, etc.
Once we're done putting our transactions into metaphorical buckets, we look at all the transactions in each bucket and perform any aggregate functions on each… and voila! That's really all there is to grouping. For the sake of completion, I'd like to note that grouping can get more complex when grouping by multiple columns, so for example group by b.bank_account_number, t.transaction_date. But to figure this out, I'd just picture a bucket inside of a bucket. So first you determine which bank account a transaction belongs to and place it over the appropriate bank account bucket, but then look at the transaction date for it and place it into the appropriate transaction_date bucket that's within the back_account_number bucket.